Harvesting¶
Harvesting is the process of automatically fetching remote metadata (ie. from other data portals or not) and storing them into udata to be able to search and find them.
Vocabulary¶
- Backend: designate a protocol implementation to harvest a remote endpoint.
- Source: it’s a remote endpoint to harvest. Each harvest source is caracterized by a single endpoint URL and a backend implementation. A harvester is configured for each source.
- Job: designate a full harvesting for a given source.
- Validation: each created harvester needs to be validated by the admin team before being run.
Behavior¶
After a harvester for a given source has been created and validated, it will run either on demand or periodically.
Running an harvester for a given source follow this pseudo-code in specific backends:
def inner_harvest():
datasets = get_datasets_from_source()
for dataset in datasets:
self.process_dataset(some_id, args1, args2, args3)
def inner_process_dataset(item: HarvestItem, args1, args2, args3):
dataset = self.get_dataset(item.remote_id)
update_dataset(dataset, args1, args2)
return dataset
The call to process_dataset is a wrapper:
1. Create the HarvestItem
2. Call the inner_process_dataset (backend dependent update of the Dataset object // without saving! See step 5.)
3. Catch errors to save the logs inside the HarvestItem
4. Update the HarvestMetadata inside the Dataset with domain, source, last_update, etc.
5. Save the updated Dataset (if not in dryrun mode)
| Property | Meaning |
|---|---|
| harvest:domain | Domain on which dataset has been harvested (ex: data.test.org) |
| harvest:remote_id | Dataset identifier on the remote repository |
| harvest:source_id | Harvester identifier |
| harvest:last_update | Last time this dataset has been harvested |
Administration interface¶
You can see the harvester administration interface in the System view.
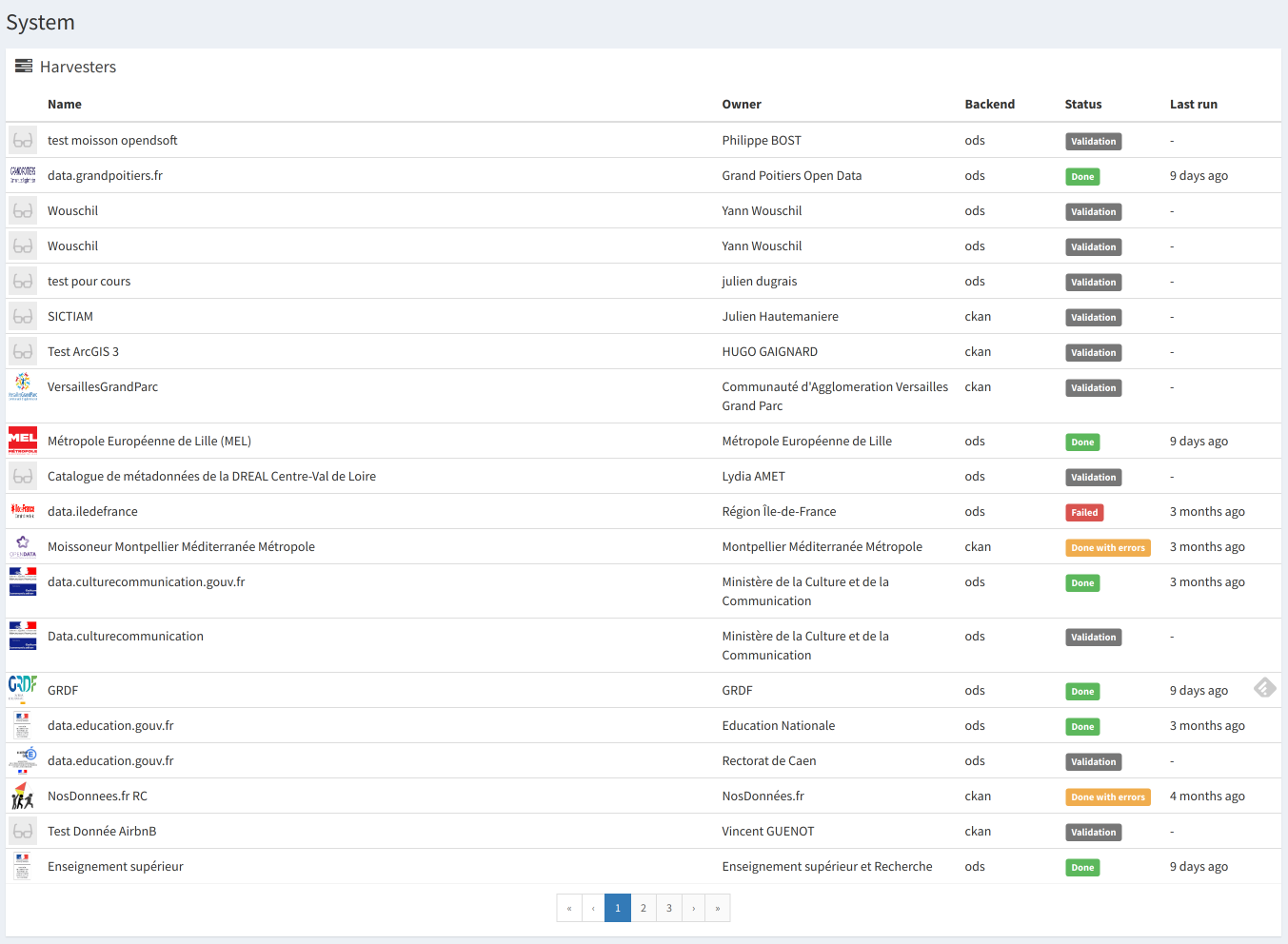
You’ll have an overview of all harvesters and their state (pending validation, last run…)
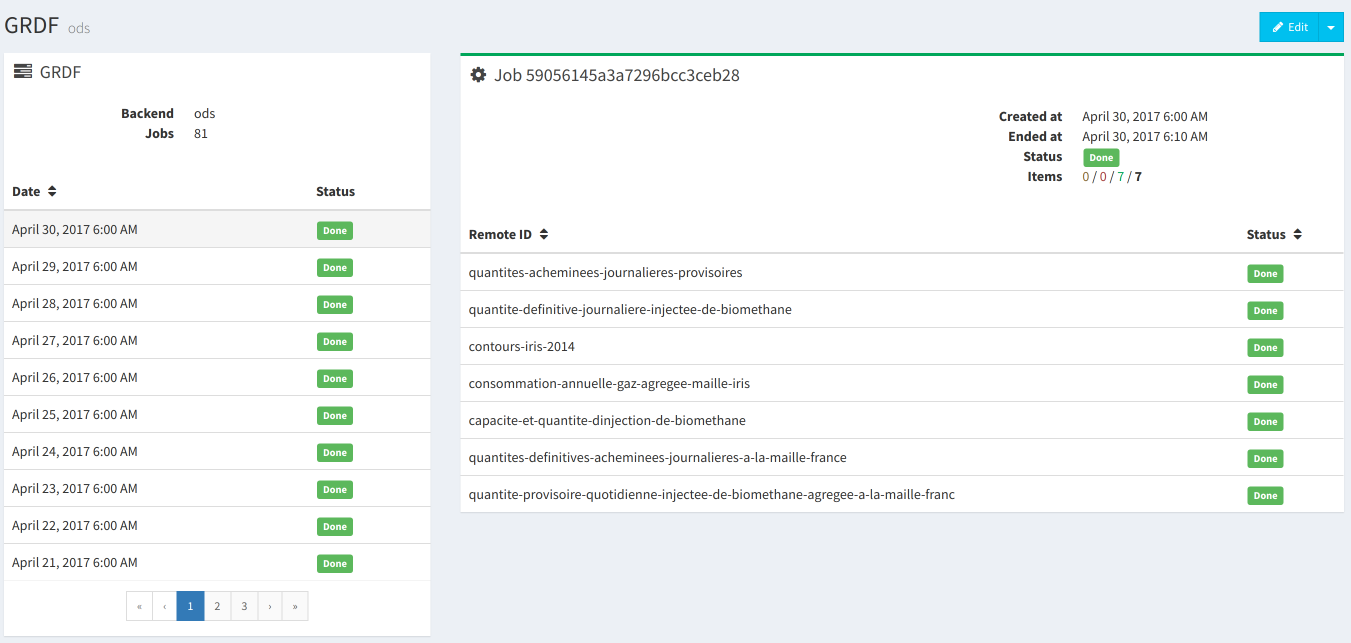
Each harvester have a full job history with every remote harvested items.
Shell¶
All harvesting operations are grouped together into the harvest command namespace:
usage: udata harvest [-?]
{jobs,launch,create,schedule,purge,sources,backends,unschedule,run,validate,attach,delete}
...
Handle remote repositories harvesting operations
positional arguments:
jobs List started harvest jobs
launch Launch a source harvesting on the workers
create Create a new harvest source
schedule Schedule a harvest job to run periodically
purge Permanently remove deleted harvest sources
sources List all harvest sources
backends List available backends
unschedule Unschedule a periodical harvest job
run Run a harvester synchronously
validate Validate a source given its identifier
attach Attach existing datasets to their harvest remote id
delete Delete a harvest source
optional arguments:
-?, --help show this help message and exit
Running harvests from the CLI¶
For local development and debugging, you can drive the full harvest pipeline from the shell. The end-to-end flow is:
- Enable the backend in
udata.cfg(see Backends) - Create a source pointing at a remote catalog
- Validate the source
- Run the harvest synchronously
- Reindex search so harvested datasets become searchable
Backend names are lowercase and match the entry point names registered by each backend module. You can list those available in your current install at any time with:
udata harvest backends
Creating a source¶
udata harvest create <backend> <url> <name>
Arguments are positional, in this order: the backend name (lowercase, see above), the catalog URL, and the human-readable name.
For example, to harvest the full data.gouv.fr catalog via DCAT:
udata harvest create dcat \
"https://www.data.gouv.fr/api/1/site/catalog.xml" \
"data.gouv.fr"
Finding the right URL¶
The DCAT backend expects a URL that returns RDF (any of RDF/XML, JSON-LD, Turtle, N3, NT, TriG) — not an HTML page. Confirm before creating the source:
curl -IL -H "Accept: application/rdf+xml" <candidate-url>
The final response should be 200 with a Content-Type such as application/rdf+xml or
application/ld+json. If you get text/html, you’re pointing at a frontend route — find the
underlying catalog endpoint via the portal’s content-negotiation redirect.
Listing and inspecting sources¶
udata harvest sources
The output includes the source name, slug, and backend. The slug is the identifier you’ll pass to subsequent commands.
Validating¶
New sources are created in a pending state and must be validated before they can run:
udata harvest validate <slug>
Running¶
For development, prefer the synchronous run:
udata harvest run <slug>
This processes the harvest in your current shell, surfacing logs and exceptions directly. It does not require a Celery worker.
udata harvest launch <slug> queues the harvest as a Celery task and returns immediately.
Use this for scheduled or production scenarios where a worker is running.
Limiting harvest size¶
When testing against a large remote catalog (e.g. data.gouv.fr’s full catalog of tens of
thousands of datasets), cap the number of items per run via udata.cfg:
HARVEST_MAX_ITEMS = 50
A small cap is strongly recommended on first runs while you verify the pipeline end-to-end.
Scoping to an organization¶
Many udata-based portals expose per-organization catalogs at /organizations/<slug>/catalog.
These are dramatically smaller than the full portal catalog and often more useful for
development:
udata harvest create dcat \
"https://www.data.gouv.fr/organizations/etalab/catalog.xml" \
"Etalab datasets"
Making harvested datasets searchable¶
Datasets are written to MongoDB incrementally as the harvest progresses. You can verify they’re arriving:
curl 'http://localhost:7000/api/1/datasets/'
However, full-text search uses a separate index (Elasticsearch/Meilisearch via
udata-search-service) which is not updated automatically by the harvest. After the harvest
completes, rebuild the index:
udata search index
Once indexed, search queries return results:
curl 'http://localhost:7000/api/1/datasets/?q=transport'
Backends¶
udata comes with 3 harvest backends (listed below) but you can implement your own backend.
In order for udata to be able to use any of those backends, they first need to be enabled
in the udata.cfg HARVESTER_BACKENDS section, like so:
HARVESTER_BACKENDS = ['dcat', 'csw*']
DCAT¶
This backend harvest any DCAT endpoint. This is now the recommended way to harvest remote portals and repositories (and so to expose opendata metadata for any portal and repository).
As pagination is not described into the DCAT specification, we try to detect some supported pagination ontology: - Hydra PartialCollectionView - Legacy Hydra PagedCollection
Fields are extracted according these rules:
Dataset fields¶
| Dataset | dcat:Dataset | notes |
|---|---|---|
| title | dct:title | |
| description | dct:description | Detect and parse HTML as Markdown |
| tags | dct:keyword + dct:theme | |
| frequency | dct:accrualPeriodicity | |
| temporal_coverage | dct:temporal | See Temporal coverage |
| license | N/A | See License detection |
| resources | dct:distribution | Also match the buggy dct:distributions |
| Dataset.extras | dcat:Dataset | notes |
|---|---|---|
| dct:identifier | dct:identifier | |
| uri | @id | URI Reference if present |
Resource fields¶
| Resource | dcat:Distribution | notes |
|---|---|---|
| title | dct:title | If missing, guessed from URL or format |
| description | dct:description | Detect and parse HTML |
| url | dcat:downloadURL or dcat:accessURL | |
| published | dct:issued | |
| last_modified | dct:modified | |
| format | dct:format | |
| mime | dcat:mediaType | |
| filesize | dcat:byteSize | |
| checksum | spdx:checksum | See Checksum |
Temporal coverage¶
Temporal coverage can be expressed in many ways. This harvester try the following patterns:
- DCAT-AP format using schema.org properties (schema:startDate and schema:endDate)
- Gov.uk Time Interval parsing
- ISO date interval as literal (ie. YYYY[-MM[-DD]]/YYYY[-MM[-DD]])
- A Single ISO month or year (ie. YYYY[-MM])
Checksum¶
| Checksum | spdx:Checksum |
|---|---|
| type | spdx:algorithm |
| value | spdx:checksumValue |
License detection¶
License is extracted from one of the DCAT distribution.
The havester try to guess the license from dct:license and dct:right.
The first match is kept.
If none matches, no license is set on the dataset.
CKAN¶
This backend harvests CKAN repositories/portals through their API and is available as a udata extension.
OpenDataSoft¶
This backend harvests OpenDataSoft repositories/portals through their API (v1) and is available as a udata extension.
Custom¶
You can implement your own backends by extending udata.harvest.backends.BaseBackend
and implementing the initialize() and process() methods.
A minimal harvester adding fake random datasets might looks like:
from udata.models import db, Resource
from udata.utils import faker
from udata.harvest.backends.base import BaseBackend
class RandomBackend(BaseBackend):
display_name = 'Random'
def initialize(self):
'''Generate a list of fake identifiers to harvest'''
# In a real implementation, you should iter over
# a remote endpoint to list identifiers to harvest
# and optionally store extra data
for _ in range(faker.pyint()):
self.add_item(faker.uuid4()) # Accept kwargs to store data
def process(self, item):
'''Generate a random dataset from a fake identifier'''
# Get or create a harvested dataset with this identifier.
# Harvest metadata are already filled on creation.
dataset = self.get_dataset(item.remote_id)
# In a real implementation you should :
# - fetch the remote dataset (if necessary)
# - validate the fetched payload
# - map its content to the dataset fields
# - store extra significant data in the `extra` attribute
# - map resources data
dataset.title = faker.sentence()
dataset.description = faker.text()
dataset.tags = list(set(faker.tags(nb=faker.pyint())))
# Resources
for i in range(faker.pyint()):
dataset.resources.append(Resource(
title=faker.sentence(),
description=faker.text(),
url=faker.url()
filetype='remote',
mime=faker.mime_type(category='text'),
format=faker.file_extension(category='text'),
filesize=faker.pyint()
))
return dataset
You need to properly expose the harvester as a udata.harvesters entrypoint in your pyproject.toml:
[project.entry-points."udata.harvesters"]
random = "canonical.path.to_the:RandomBackend"
The easiest way is to start from the dedicated cookiecutter template:
pip install cookiecutter
cookiecutter gh:opendatateam/cookiecutter-udata-harvester
This will create a new package with a harvester skeleton on which you can start hacking.
You may take a look at the existing backends to see exiting implementations.
Debugging¶
Debugging the harvesting code may be difficult as it’s run in Celery, asynchronously, and using a breakpoint (to drop into a pdb)
is kind of a pain.
Another trick could be calling the synchronous version of the harvesting command:
# Drop a `breakpoint()` somewhere in your harvesting code, then:
$ udata harvest run <source_id>